Data Management in RONIN
Effective data management is crucial in the cloud but with so many storage options available, things can be a little confusing. This blog post summarises all you need to know about the different data storage options in RONIN and when to use them.


Researchers strive to have well-organised, efficient and cost-effective data management strategies in place; however, data management is often the bane of every researcher's existence and data storage can get messy if not properly planned out. Fortunately, RONIN makes data management a breeze in the cloud, though with multiple storage options available, it can be a little confusing to decide which storage methods are best. Of course there's no simple answer and it all comes down to what works best for you and your workflows, but this blog post summarises your different data storage options in RONIN and provides some general suggestions for data management.
Storage Method 1: Object Storage (S3)
SECURITY & COST
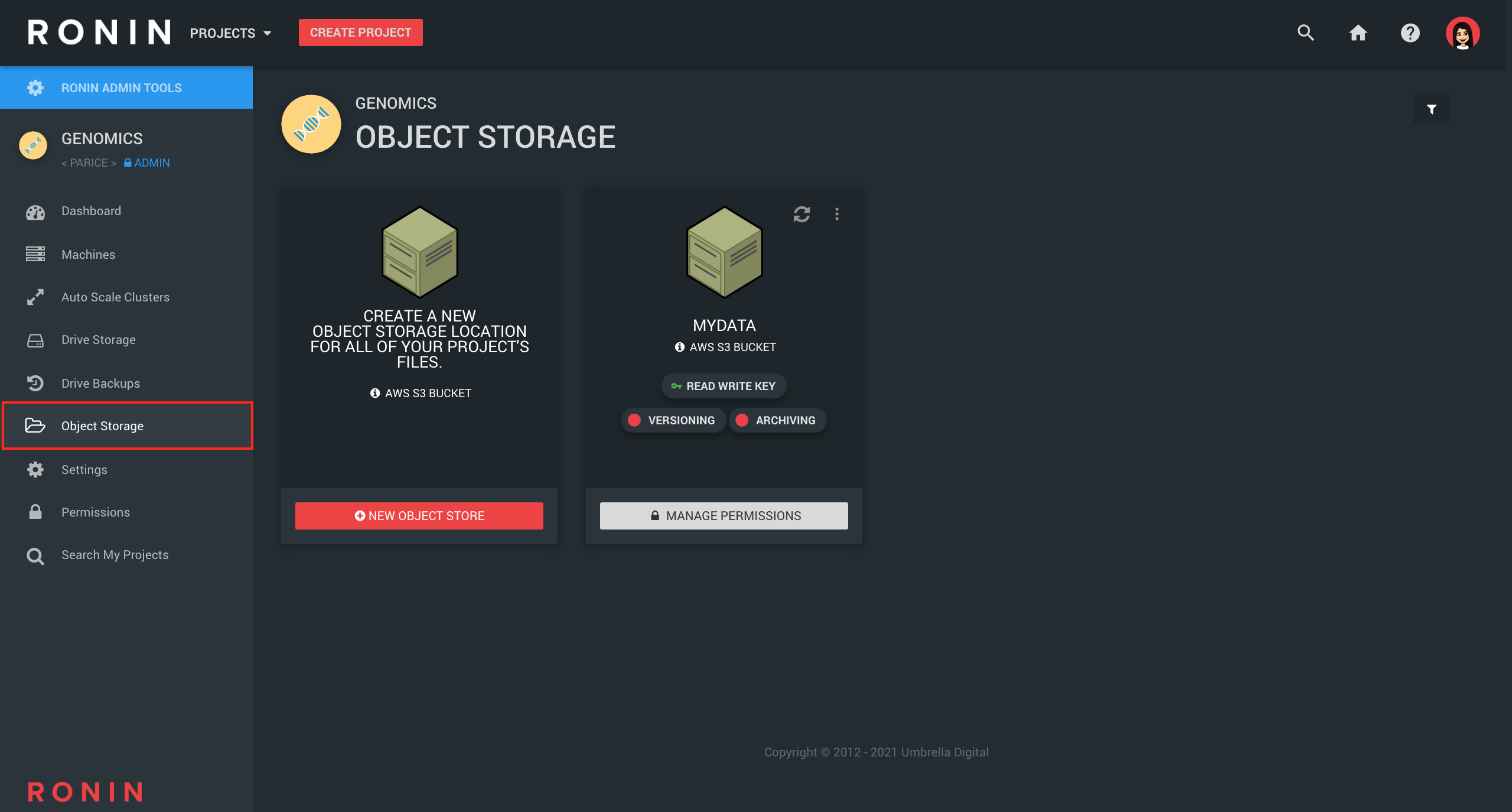
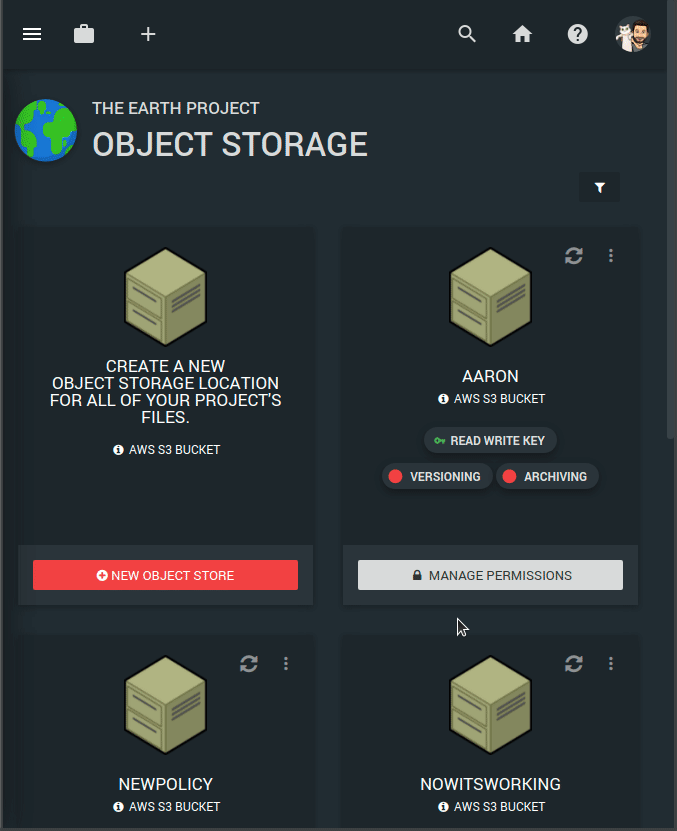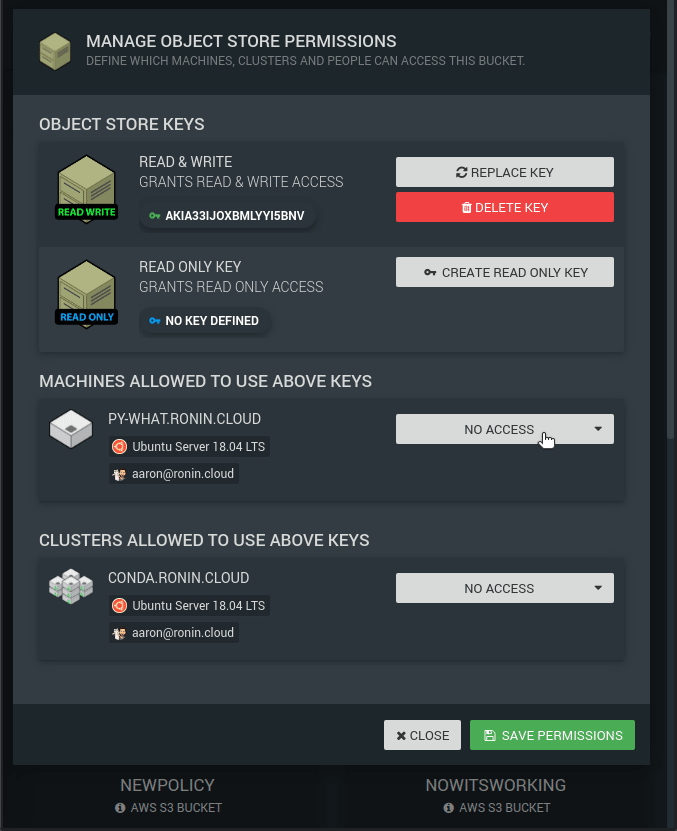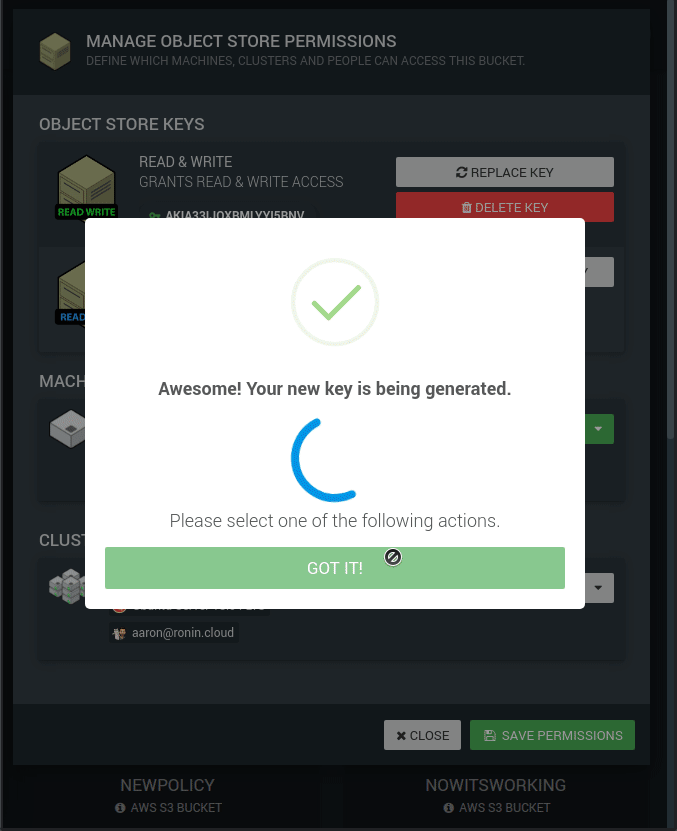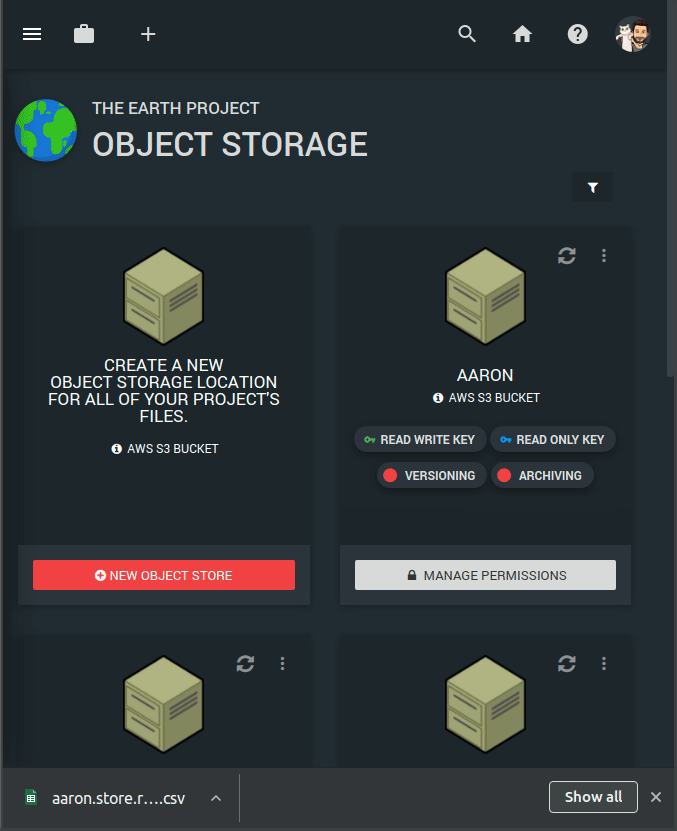
Object storage (also known as Simple Storage Service or S3 in AWS speak) is the cheapest and the "safest" location to store all of your files in the cloud. Every file uploaded to an object storage bucket is automatically duplicated across multiple physical locations in the same geographic region, meaning that on average you might lose a file every few million years. Access to object storage buckets is tightly controlled based on access keys which can either be Read & Write or Read Only. Furthermore, for highly sensitive data our RONIN ISOLATE product provides a second layer of protection by restricting which machines or clusters are allowed access to such keys (see GIF below). Object storage is billed per GB of data per month and usually equates to ~$0.025 (US) per GB depending on your region. For a full overview of the costs for your region check out https://aws.amazon.com/s3/pricing/.
VERSIONING/ARCHIVING
With RONIN, you can easily enable versioning of your object storage bucket if you would like to be able to revert to previous versions of files, or recover recently deleted files, though be aware of the additional charges that are associated with this. You can also turn on archiving (to S3 Glacier) after a designated period of time for cheaper, long-term storage of files (~$0.0045 GB/month which equates to ~$54 US per TB per year depending on your region) that can be recovered in a matter of minutes if needed. Refer to our previous blog post on object storage for more details on how to create your own object storage bucket in RONIN and enable versioning/archiving.
DATA TRANSFER
It's important to note that buckets can only be used for storing input and output data that can then be transferred to and from machines when needed. One of the main advantages of object storage (other than its affordability and durability) is that large datasets can be transferred to and from object storage buckets very efficiently with the AWS Command Line Interface (CLI). The AWS CLI takes advantage of multi-threading to ensure data transfer is as efficient as possible and also requires very little memory (RAM). This ensures that large datasets can be uploaded to the bucket or downloaded from the bucket within minutes. Refer to this blog post to see how to set up and use the AWS CLI to upload your data to an S3 bucket.
Please note that while there are no data transfer costs for uploading data INTO the cloud (i.e. from your personal server to your object storage bucket), there are download costs associated with transferring data OUT of the cloud (i.e. from your object storage bucket to your personal server) which is roughly $0.09 per GB for the first 10 TB of data.
Some programming languages such as python or R can directly read in files from object storage which prevents the need for these files to be stored locally on the machine; however, this method should only be used for small input datasets such as basic csv or text files. Files can also be transferred directly from your personal computer to your machine (instead of via object storage) using SFTP through the command line or using Cyberduck; however, this is also only efficient for relatively small files.
FILE MANAGEMENT
If you end up with a large file hierarchy within your object storage bucket, it can sometimes become a little difficult to keep a track of all of your files and folders using the AWS CLI, especially if you just want to quickly grab a small output file from your bucket to view or save on your personal computer. A great solution to be able to easily see and manage what's in your bucket and upload or download small files to and from your personal computer when needed is to configure your bucket with the desktop application Cyberduck. See our Cyberduck tutorial here. Cyberduck has loads of other helpful features too such as the ability to quickly grab the S3 paths to certain files or folders, or to automatically delete them after a certain amount of time. Overall, Cyberduck is a great way to interact with the files within your object storage bucket.
Storage Method 2: Drive Storage (EBS)
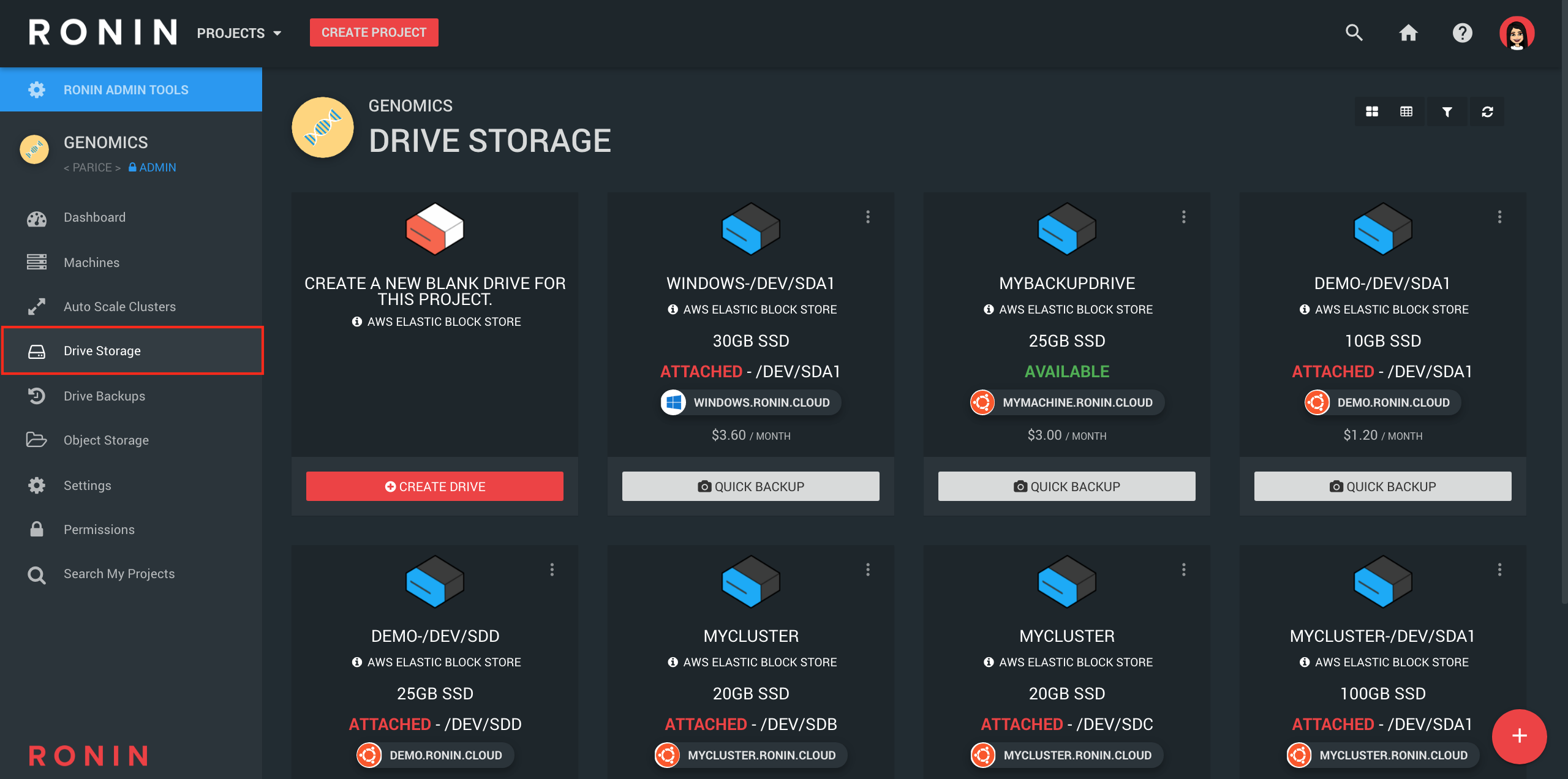
DRIVE TYPES & COST
Drive storage (also known as Elastic Block Store or EBS in AWS speak) refers to storage that can be attached to machines or clusters in RONIN (similar to a hard drive or USB drive). This is where you should store your input, output and any intermediate data from the analyses you are currently running on the machine. Drives are more expensive than object storage and you will always pay for the total drive size, even if you are not using the full capacity. This is why we don't recommend storing data on drive storage for the long-term. You should move data to object storage (as above) or create a backup of the drive (see Storage Method 3). There are a number of different drive types with different prices (dependent on your region) that are suitable for certain workloads (see below), though the General Purpose SSD is the standard choice in most circumstances. You can check out this blog post to see how to create, monitor and manage your storage drives in RONIN.

DRIVE MANAGEMENT
When you create a machine or cluster in RONIN, your operating system will always be installed on a "root" drive. The root drive can be used for storing data too, though it is often better to attach a separate storage drive (or use the "shared" storage drive on clusters) for your datasets because any "non-root" storage drives can easily be detached and reattached at any time. This gives you the flexibility to be able to move data around to different machines - see this blog post for more information. Additionally, you can easily create a backup of any storage drives which can then quickly be restored to a drive when needed again (see Storage Method 3 for more information).
Note: Additional storage drives (i.e. non-root drives) that are added to machines during the machine creation process are automatically mounted to the
/mnt/directory; however, if you later attach a drive to an existing machine you will need to mount that drive yourself. Refer to this blog post for more information.
Storage Method 3: Drive Backups (Snapshots)
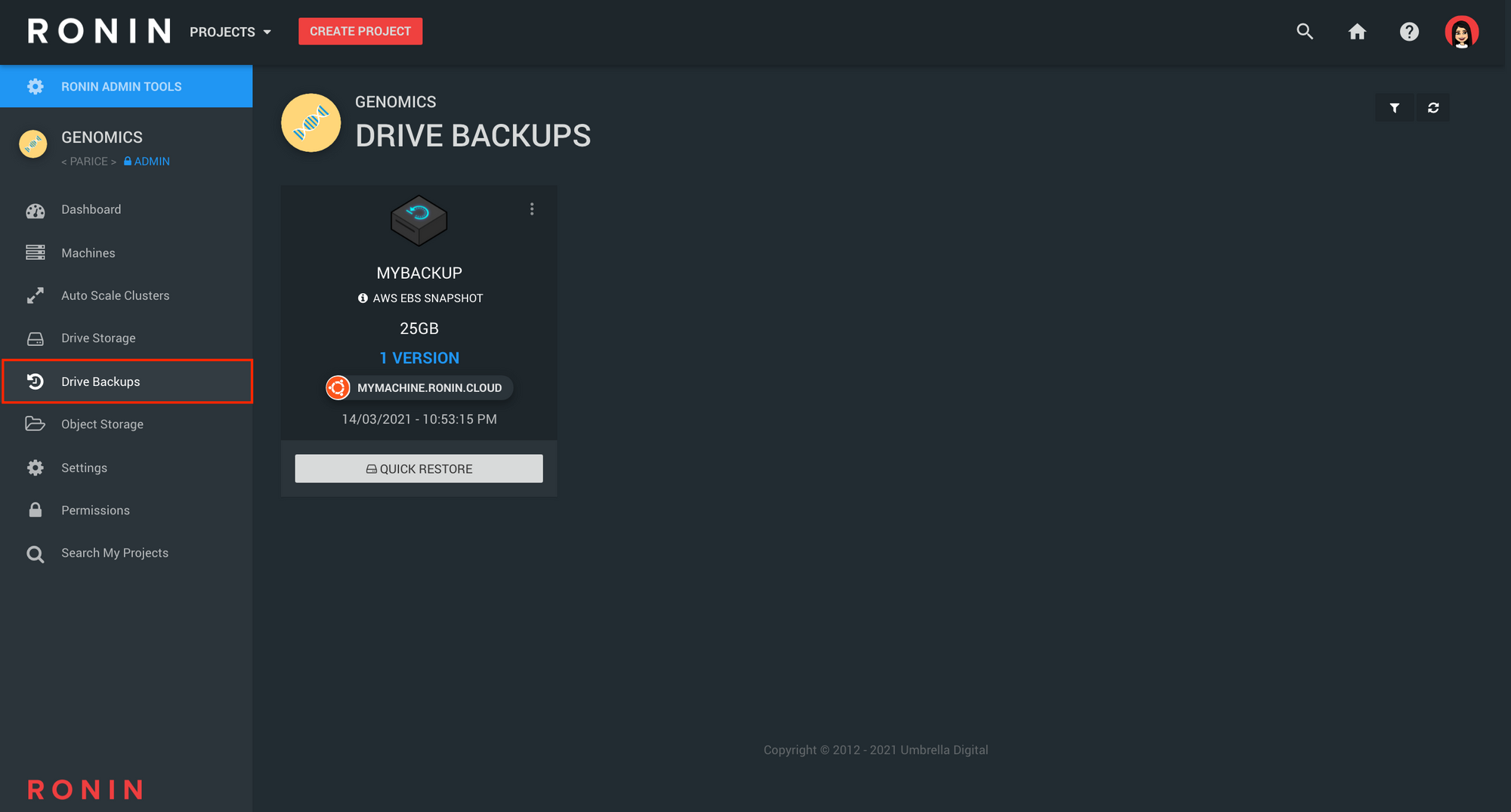
Drive backups (also known as Snapshots in AWS speak) are a great intermediate between object storage and storage drives. In RONIN, you can create a backup of any storage drive within your project which will create an exact copy of that drive with all the files on it at that point in time and store this information in object storage. This means it will be similar in price to object storage (there is a slight additional fee for snapshots of ~$0.055 per GB per month) but with the added benefit that it can quickly be restored back to a storage drive that can be reattached to a machine when needed. This is really useful for large or complex input datasets that may be used frequently within a project by one or more people as it prevents the need for data to constantly be manually copied back and forth to object storage but is more affordable than constantly keeping the data on a storage drive. Refer to this previous blog post to see how to take snapshots of drives in RONIN. In addition, multiple versions of drive backups can be created across different points in time so that you can always revert back to a previous backup if needed - see this blog post for more information.
Storage Method 4: Instance Storage
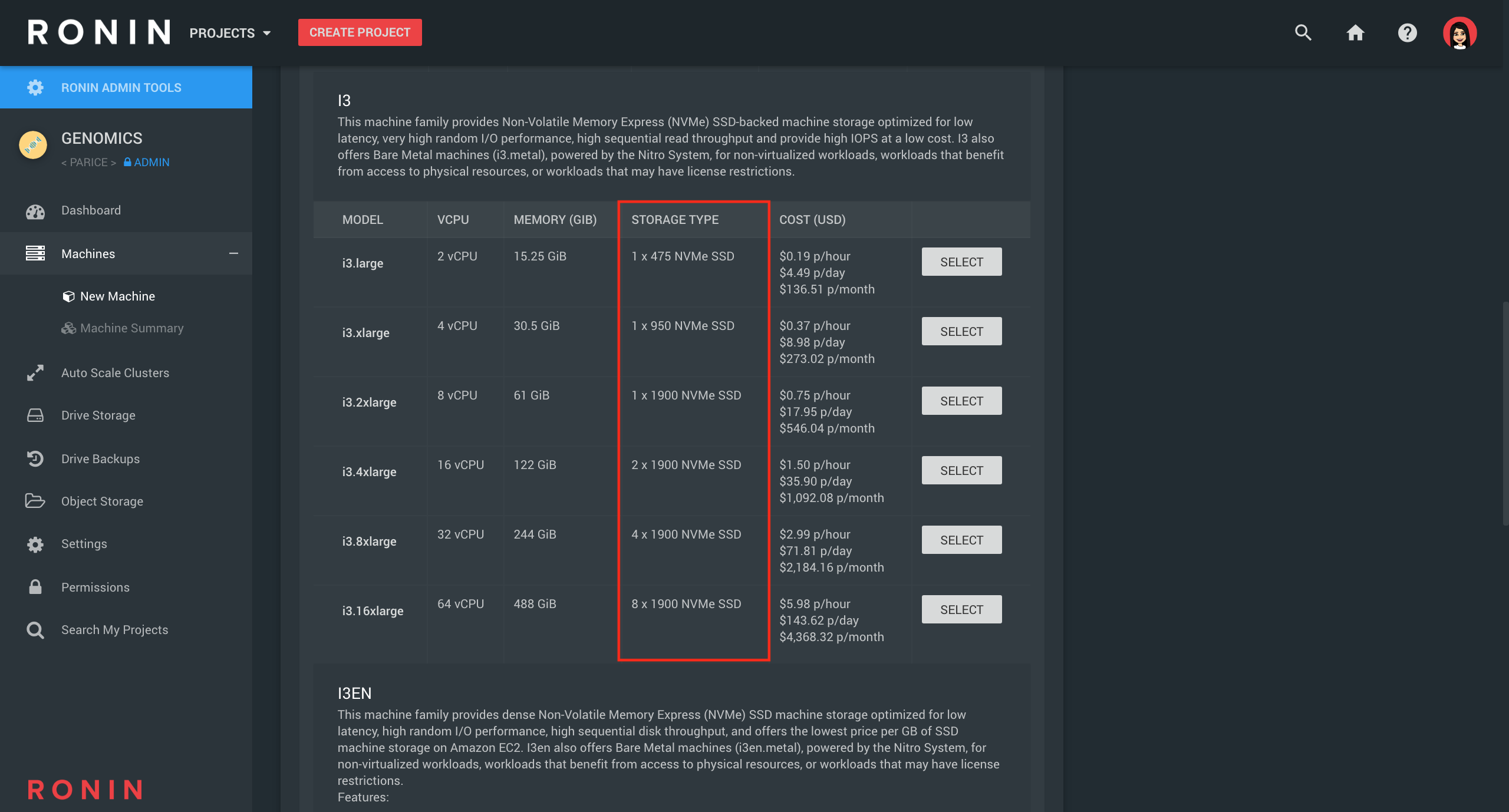
When creating a new machine or cluster in RONIN, you may notice that some of the machines you can select, especially the "Storage Optimised" machines, have some associated storage (in GB) listed in the "Storage Type" column as shown above. This storage is known as an "instance store" and these listed storage drives are physically attached to the machine. This makes them faster than drive storage. They have a fixed capacity and type, and are erased when the machine is stopped. These drives are included as part of the machine's usage cost and can be used like drive storage as above; however, you must transfer any data that you want to keep off instance storage (i.e. to object storage or to drive storage) before you stop or terminate your machine.
Note: Standard EBS storage drives can still be attached to machines with instance storage. Machines without instance storage will have "EBS Only" written in the "Storage Type" column. Because these machines don't have any physically attached storage you must use either the root storage drive or attach your own EBS storage drive to store your data.
You should now know everything you need to get started with data management in RONIN so go forth and get those files into line!
