Working with Object Storage (AWS S3 and Glacier) in RONIN
We've been busy here at RONIN, simplifying Amazon's S3, versioning and Glacier, so that everyone can benefit from what the cloud has to offer, not just tech savvy nerds like us.



One of the hardest parts of Cloud Computing is getting your data into the cloud and being able to utilise it effectively across multiple operating systems, while collaborating with teams that have different goals, then storing it in the most cost effective way possible. That's a big task for even the most advanced cloud computing users. Fortunately, object storage makes all of this possible and we've been busy here at RONIN, simplifying object storage, versioning, and archiving, so that everyone can benefit from what the cloud has to offer, not just tech savvy nerds like us.
What the heck is Object Storage?
Object Storage is, well, just a type of storage for your data. Similar to file storage, like what you would have on your computer right now. An "object" is basically just any file that you would like to store, and your "Object Store" or "Bucket" is the place you store it.
There are multiple advantages to using object storage instead of standard file storage in the cloud, for example, incredibly fast file transfer speeds, reductions in cost, ability to archive files, ability to enable versioning of files, and almost 100% availability and durability. Every file put in an Object Store is automatically duplicated across multiple physical locations to protect data from site-level failures, errors, and threats. Overall, Object Storage is the most cost effective and secure location to store your data in the cloud. However, it is important to note that Object Storage is often not suitable or efficient for direct processing of files, i.e. the files will often have to be transferred to standard file storage (i.e. a storage drive that is attached to your machine) prior to processing. If you would like more information on how object storage compares to other storage options in the cloud, check out this blog post and this link.
So... What does Amazon S3 mean?
On our simplification rampage of cloud computing, we believe Object Storage is the most descriptive way to describe what Amazon S3 (Simple Storage Service) does, so Object Storage and S3 mean the same thing.
You may also be interested to know that our backups / snapshots are stored as objects, providing the same durability, scalability and availability for your storage drives.
How does object versioning work?
Versioning allows you to keep multiple variants of a file in your object store, meaning you can preserve, retrieve, and restore every version of every file you upload to your object store. Versioning can also help you recover files from accidental deletion or overwrite.
It is important to note that normal rates apply for every version of file stored in Object Storage. So, if you have three versions of an object stored, you are charged for three objects.
And what about Archiving / Amazon Glacier?
Archiving is an optional life cycle of this data. Archiving can move files to an even cheaper version of storage; for example, when you are finished processing the data and want to store your results somewhere safe and affordable for an extended period of time. Archived data can be retrieved back to standard storage in milliseconds to hours (depending on the Glacier tier selected - see Step 5 below) should you ever need to use the data again.
Glacier is Amazon's way of describing archiving, effectively 'putting your data on ice'. Yep, they're nerds who like puns too.
What are we waiting for? Lets begin!
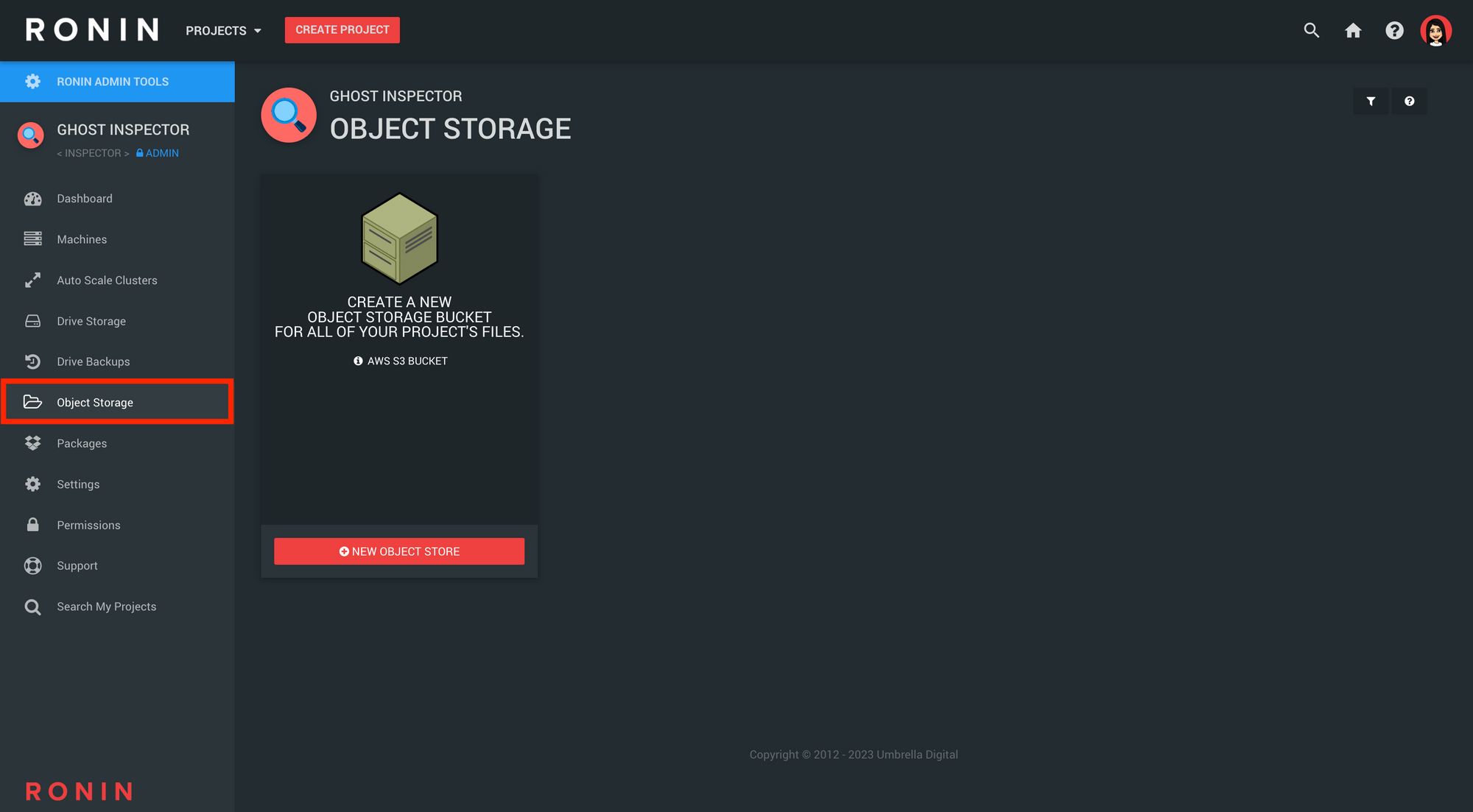
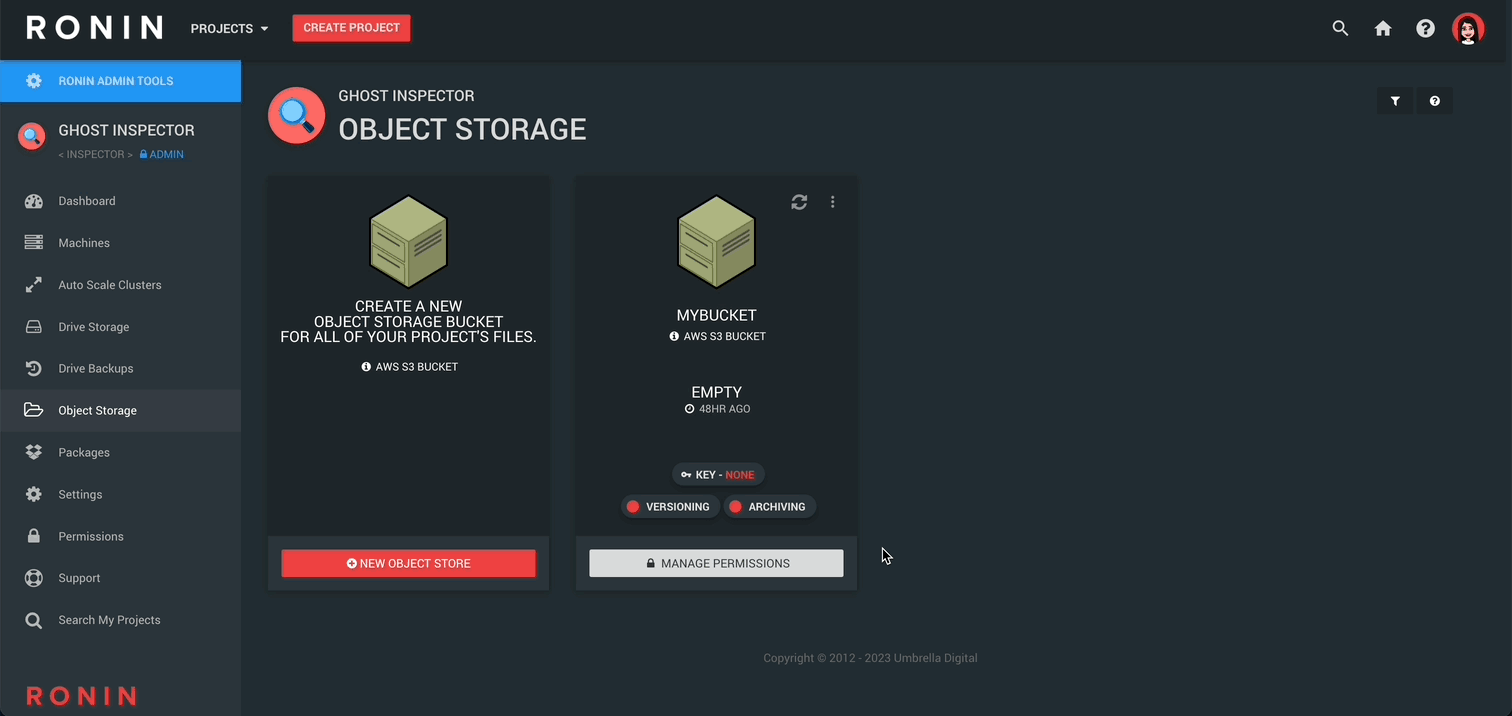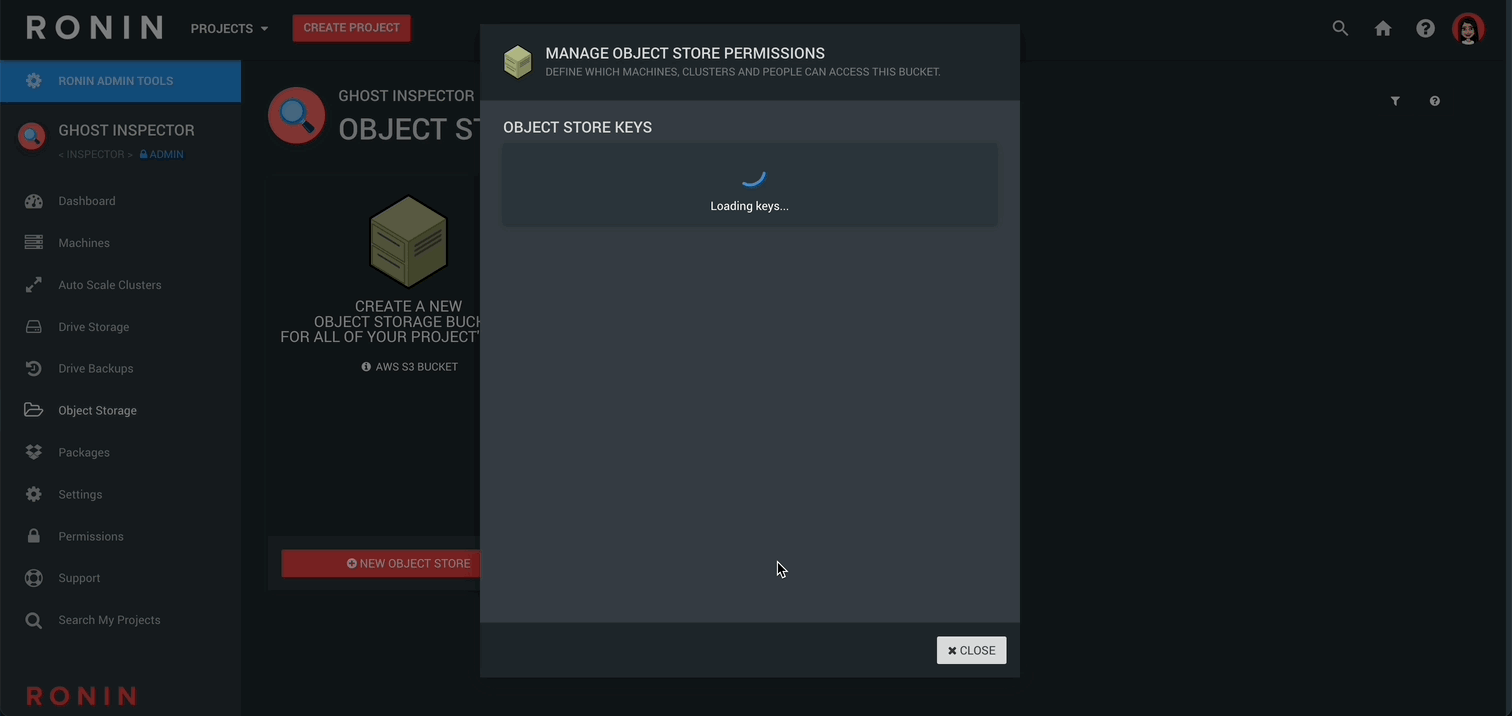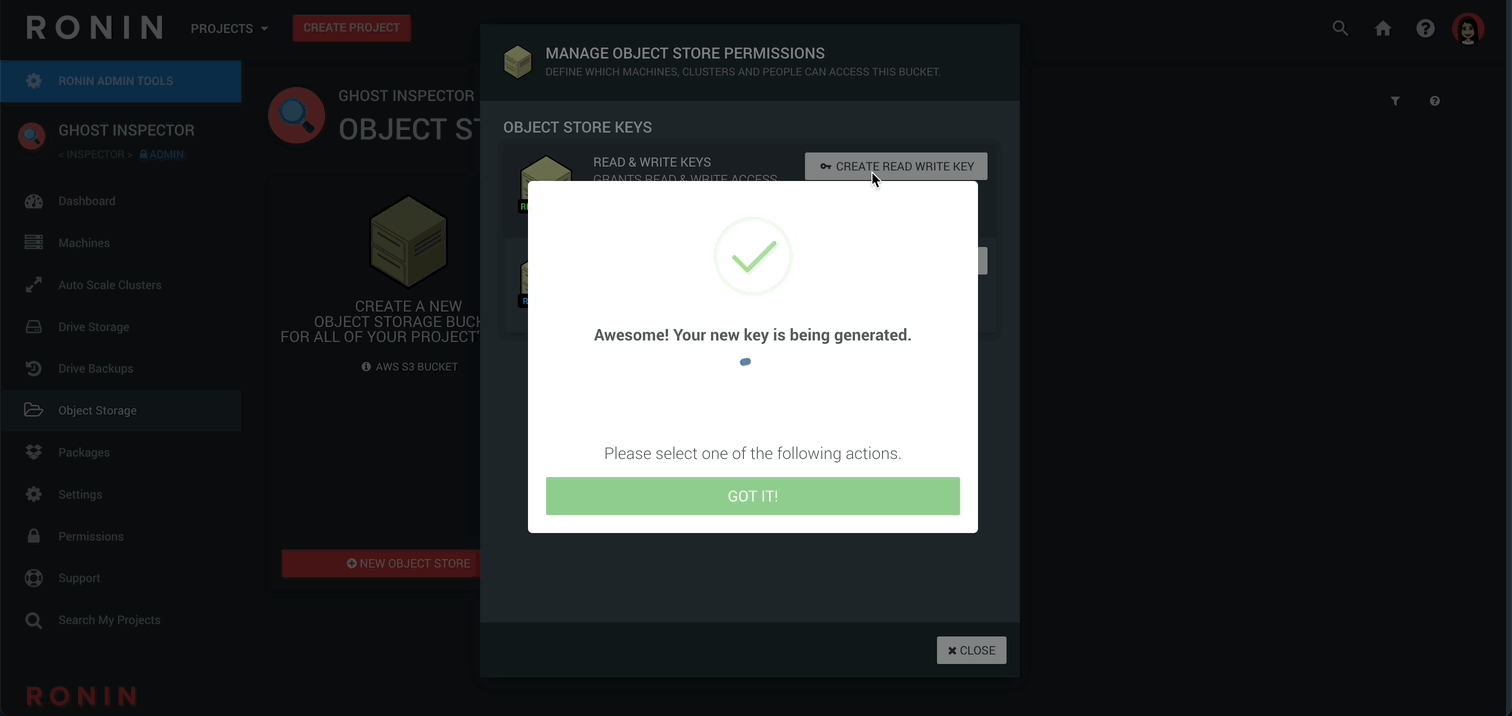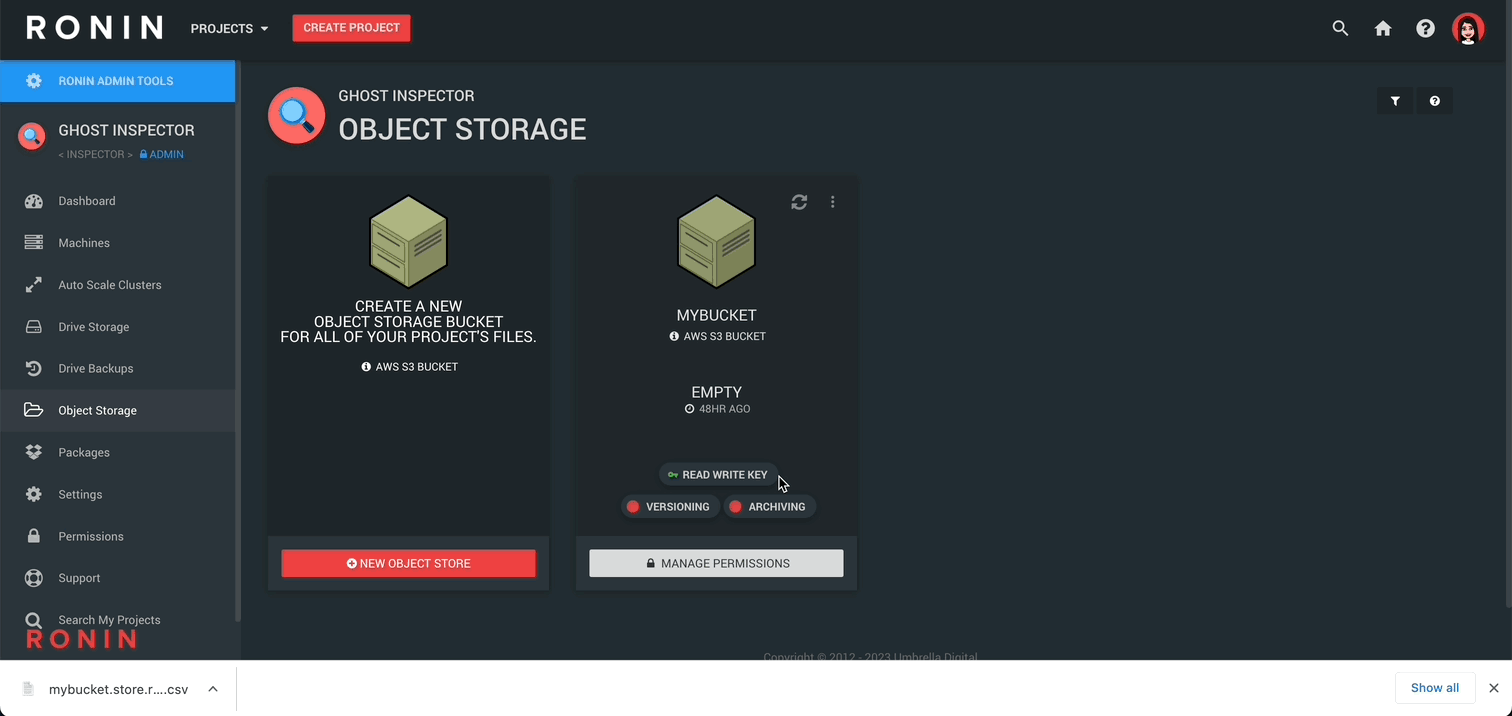
Step 1 - Navigate to the Object Store screen
To create your very own object store, Log in to RONIN, select a project, and click Object Storage in the left navigation pane:
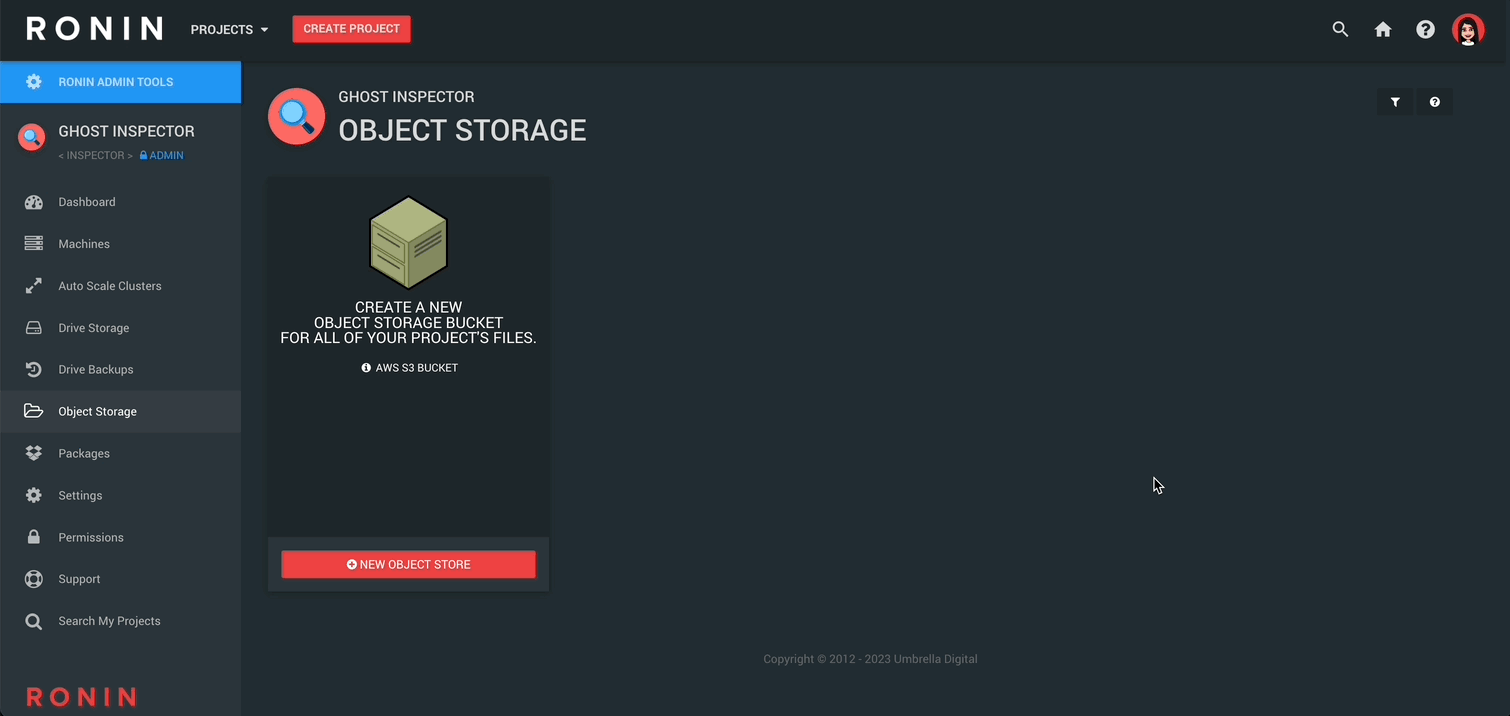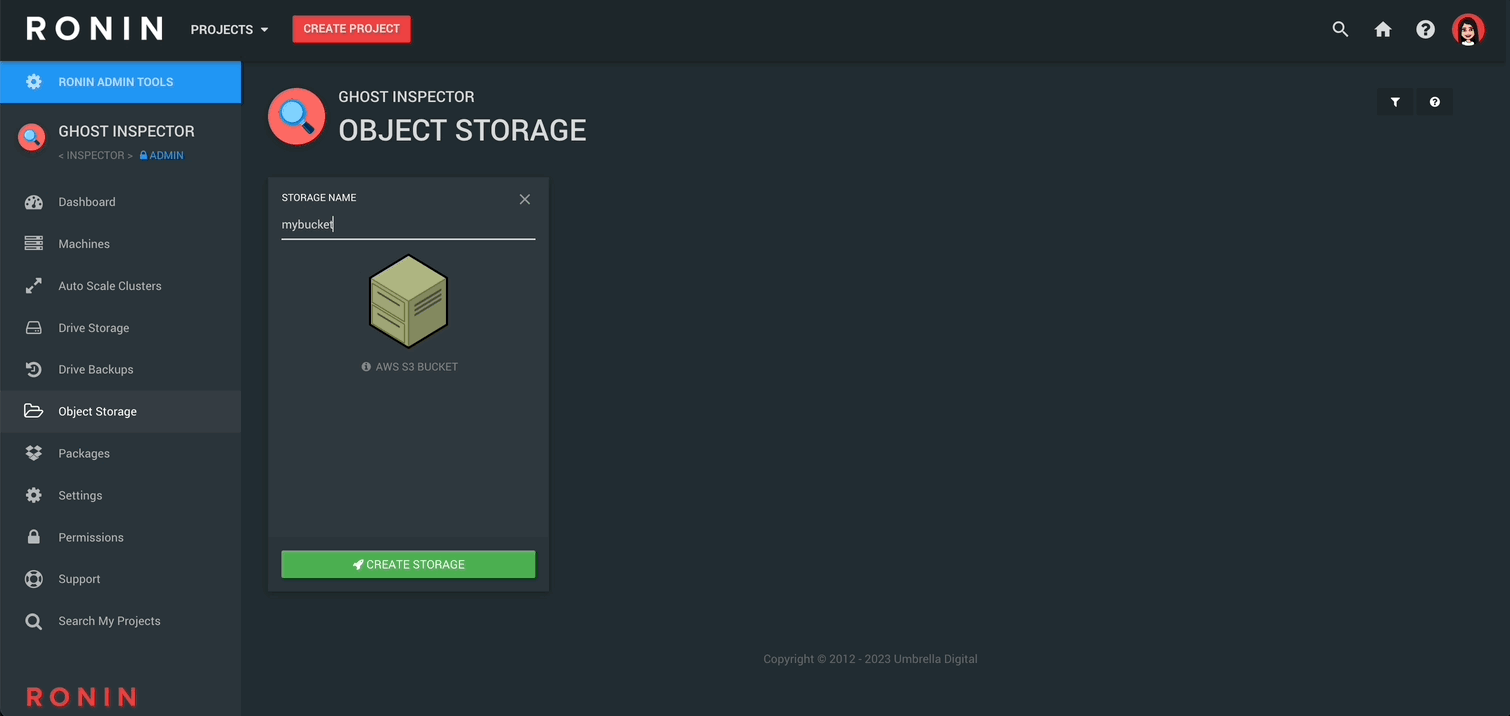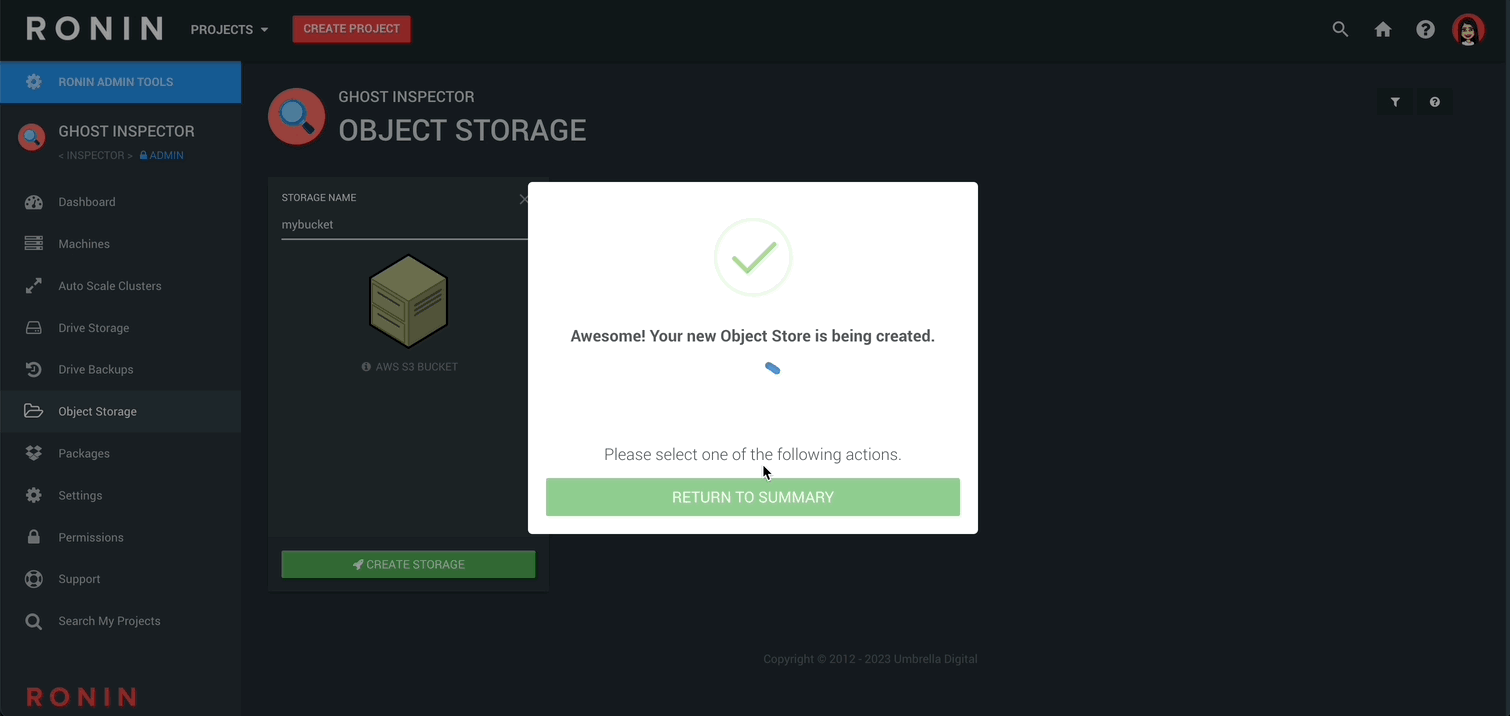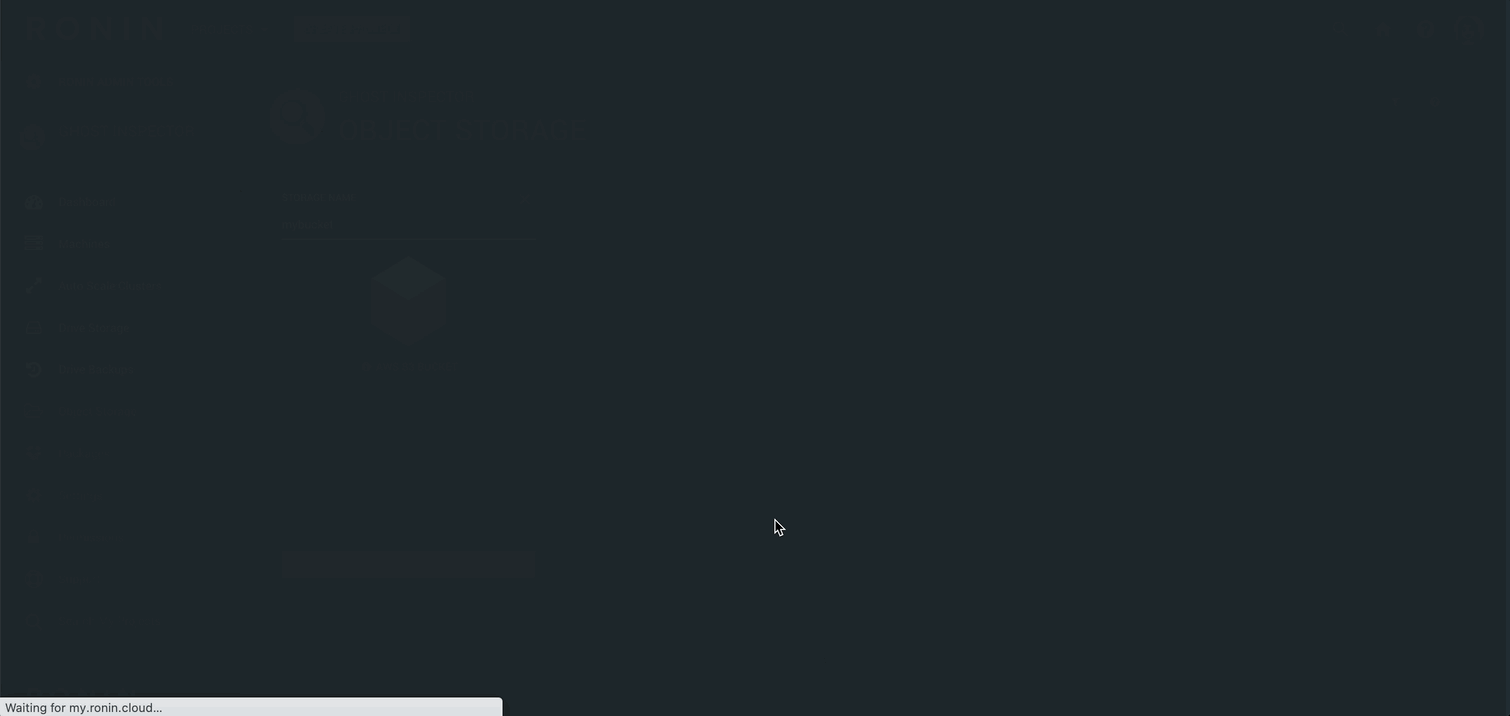
Step 2 - Create your Object Store
On the first card, click NEW OBJECT STORE, name your new object store and then click CREATE STORAGE:
Next, RETURN TO SUMMARY to see your newly created object store.
Behold our newly created Object Store!
Step 3 - Generate your Secret Access Key
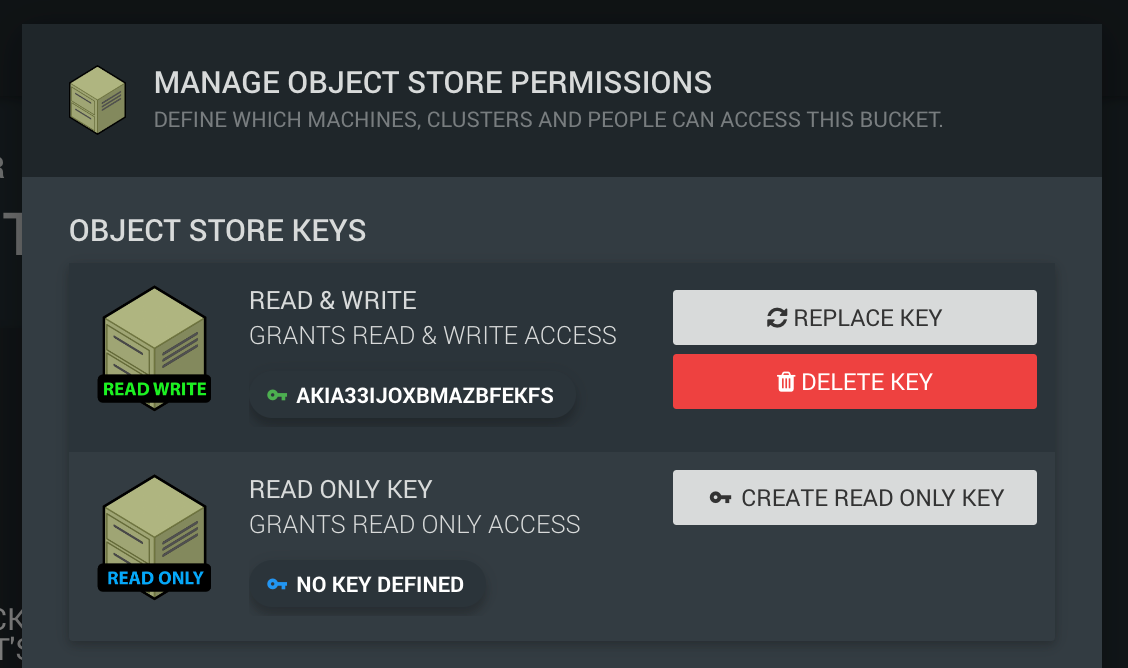
Now click MANAGE PERMISSIONS and create either a READ & WRITE key or READ ONLY key:
This will create your secure access key that will allow you to access your object store. Your browser will automatically download a csv file with your key credentials into your downloads folder for convenience.
This access key is just like a real world key, and anyone with this key / file can access your object store. Be careful who you share it with and keep it in a safe place!
Note: You can also regenerate / delete a key whenever you like, meaning the previous key will no longer work. Click the Manage Permissions button on your object store and select replace / delete key.
Once you've generated your key, you can now connect to your store with either Cyberduck or the AWS CLI (see Step 6 Below).
Step 4 (Optional) - Turn on Versioning
By turning on versioning, all files you modify within your Object Store will be preserved each time they're modified. This is very useful for times you make mistakes and need to restore something that was working before.
Because you're using Object Storage (as explained above) you are only storing the modifications of these files, and not the whole file over and over, but you can still restore a file to it's former glory.
To turn on versioning, click the Versioning button and then click ENABLE VERSIONING
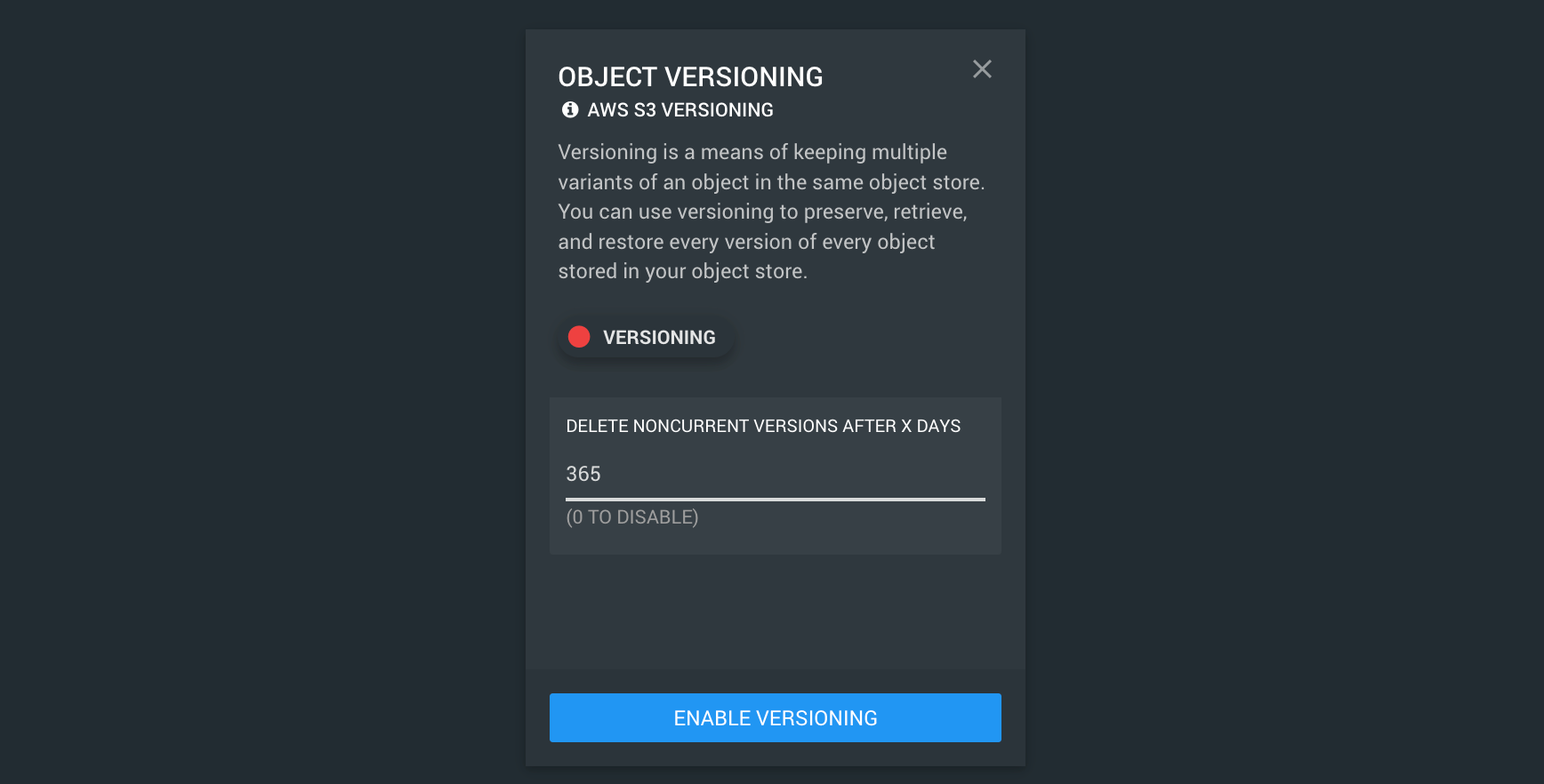
Note: You will also have the option to specify after how many days you would like non-current versions of files to be deleted. This feature is disabled by default (value set to 0); however if you would like any non-current versions of files to be deleted after say 1 year, just set this value to 365. You can change this value at any time.
Step 5 (Optional) - Turn on Archiving (Glacier)
With another optional cost saving / data backup method, you can specify how often files are archived.
This won't affect your files in s3, instead it will create backup files on very cheap storage at an interval of your choosing. The trade off is those files take a little while to become available again.
There are three different Glacier archival tiers available:
- Glacier Instant Retrieval - ideal for archive data that needs immediate access. Data retrieval in milliseconds, ~$0.004 per GB (region dependent).
- Glacier Flexible Retrieval (Formerly Glacier) - ideal for archive data that does not require immediate access but needs the flexibility to retrieve large sets of data at no cost. Data retrieval from minutes to hours (minutes incurs some cost, whereas hours is free), ~$0.0036 per GB (region dependent).
- Glacier Deep Archive - ideal for archive data that needs to be retained for 7—10 years or longer to meet regulatory compliance requirements. Data retrieval within 12 hours, ~$0.00099 per GB (region dependent).
For more information on the different Glacier storage classes, click here.
To turn on archiving, click the ARCHIVING button, select the tier that best suits you, enter after how many days you would like your files to be moved to this archive tier, and then click ENABLE ARCHIVING.
If your object storage bucket also has VERSIONING enabled, you will be able to select whether you would like only the current versions of files to be archived, or ALL versions of files to be archived.
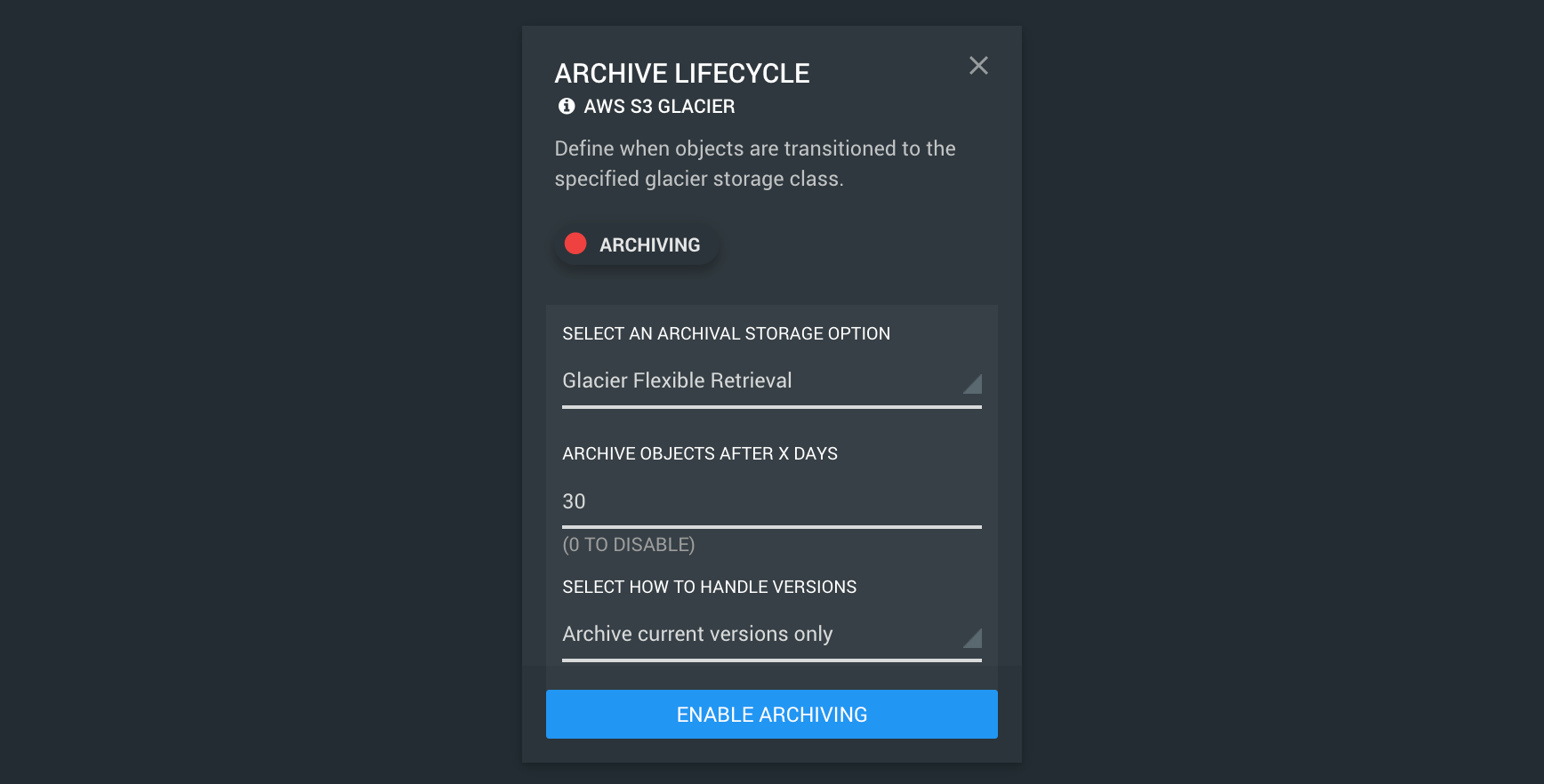
Note: Archived data can move down the storage tiers listed above, but not up. For example, if you first set your object storage bucket to archive files to the Glacier Instant Retrieval tier, you can later change your tier to Glacier Deep Archive at any time, and any files already in Glacier Instant Retrieval (or standard storage) will be moved to Glacier Deep Archive after the specified number of days. However, if you initially set Glacier Deep Archive, and later want to change to Glacier Flexible Retrieval, only un-archived files (that are in standard storage) will be archived to Glacier Flexible Retrieval, files already archived in Glacier Deep Archive will remain there.
Step 6 - Connect to your Object Store
If you are working with small files and would like a user-friendly interface to interact with your object store:
Click here to see how to connect with Cyberduck
If you are working with large files, or lots of files, and would like a fast way to upload/download data to your object store via the terminal:
Click here to connect with AWS Command Line Interface
Some other common tools for connecting to your object store include:
Once you've transferred some data to your object store you will be able to see the total size of the data that is in there, including the amount of data that has been archived (if archiving is enabled):
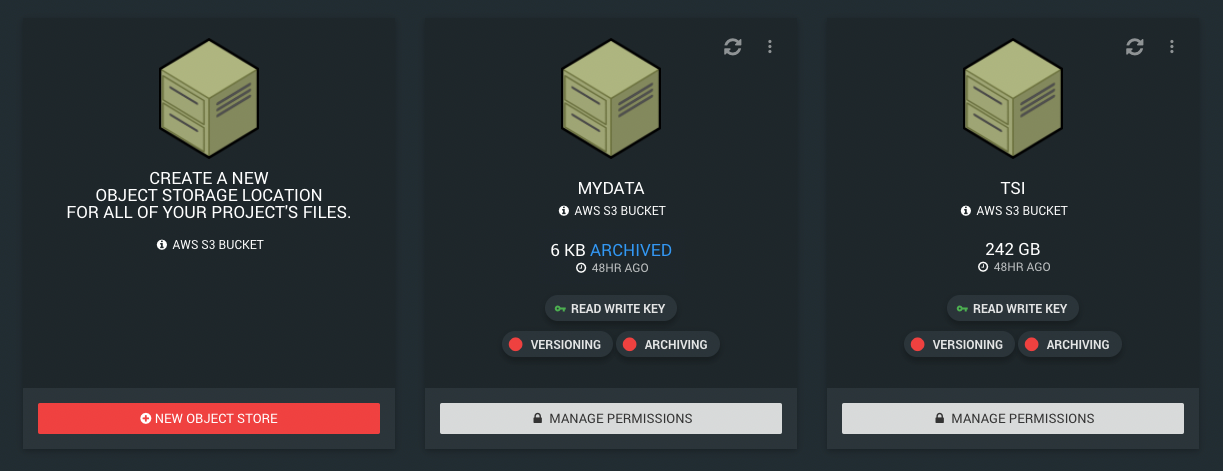
Note: Object store sizes are calculated and updated by AWS every 48 hours.
Step 7 (Optional) - Empty your Object Store
Please refer to our handy blog post on the different way you can delete files in your object store or completely empty it when needed:
Step 8 (Optional) - Delete your Object Store
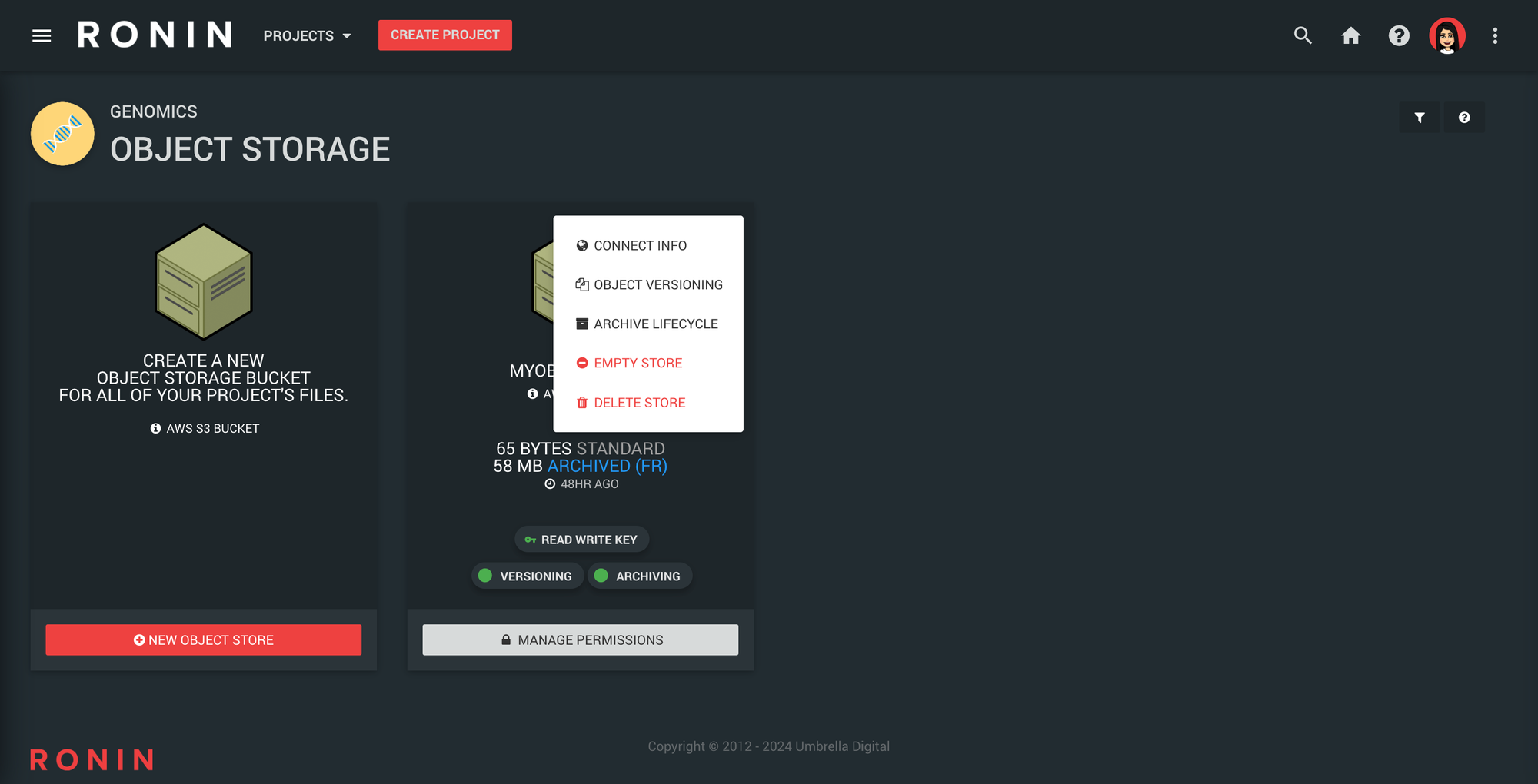
Object stores can only be deleted once they are completely empty. To delete the object store, click on the 3 dots in the top right hand corner of your object storage card and click "DELETE STORE". RONIN will warn you if the bucket is not yet empty, otherwise it will delete the bucket for you.
Want to learn more about Object Storage? Check out the collection of blog posts below:
