What We Talk About When We Talk About Supporting Researchers on the Cloud
It's obvious, isn't it? The purpose of research computing support is to enable researchers to conduct more research faster, to make new discoveries, to publish more influential papers, obtain more grant funding, and train the next generation. But in practice...


It's obvious, isn't it? The purpose of research computing support is to enable researchers to conduct more research faster, to make new discoveries, to publish more influential papers, obtain more grant funding, and train the next generation. But in practice, research IT measures tangible things such as high performance computing (HPC) cluster utilization and responsiveness of IT staff to support requests, which are difficult to link to the impact of research that takes years to materialize. Research computing needs are incredibly diverse. After spreading an IT team across the basics (compute, storage, security, networking) there may be little energy left to actually help researchers use advanced computing technology to tackle research problems in novel ways.
Adopting a Cloud Mindset
Cloud computing changes this equation. When researchers can automatically and securely provision their own compute and storage resources — including high performance computing clusters — IT admins can focus on helping researchers with the research software that is closest to getting their work done. Unlike on-premise resources, which are shared across multiple users to increase utilization, cloud computers are intended for a specific purpose and generally designed for use by one person. Installing only the software that is required for a specific research workload results in smaller and less expensive images and furthers sharing and reproducibility. Thus, the problem of research software support changes from one of supporting hundreds of packages and IT services on shared on-premise infrastructure to supporting individual researcher workflows for their labs on automatically provisioned infrastructure. Even then, the variety of domain specific research software needs is so vast that it is difficult to know where to begin.
RONIN Solutions
The RONIN Machine and HPC Package Catalogs and RONIN Link, our desktop application, work together to scale research IT capabilities by automating common software installation tasks.
Package Catalogs
The Package Catalogs offer packaged machines and clusters that have specific software packages installed on them. These are starting points that cover the most common utilities for all researchers within RONIN. Researchers launch the package that is closest to their needs; or expressed differently, the package that comes with the things they are least comfortable with installing themselves.
The catalogs are created, controlled and vetted by IT admins, so that researchers can only launch these machines and cluster starting points. For example, catalog offerings can be configured to run any required logging or security-related services. This guarantees researchers a secure, compliant and functional foundation. To create a packaged machine, an IT administrator can either specify an existing AWS Amazon Machine Image identifier or install software on a base operating system image and package a machine within a project. Because they have more moving parts, clusters must be created and packaged using the RONIN user interface after installing the required software.
Spack Package Manager
This works for many software packages, but what about HPC applications that need to be tuned specifically for different architectures? Each cluster is a new creation with a different network and node configuration, and applications often need to be recompiled to run efficiently. Now that's a real problem. RONIN tackles this by leveraging Spack, a package manager that handles the complexity of optimizing applications for a more-than-comfortable number of combinations of architectures, compilers and programming models. RONIN clusters launch pre-configured with Spack, which as of this writing includes nearly 6000 mainline packages. By leveraging recipes created for popular applications, research IT can provide sophisticated computing support while giving researchers the full flexibility of AWS. Researchers can install, compile and optimize an application on-demand using Spack with the command "spack install", because all of the HPC optimization work is described by the Spack recipe.
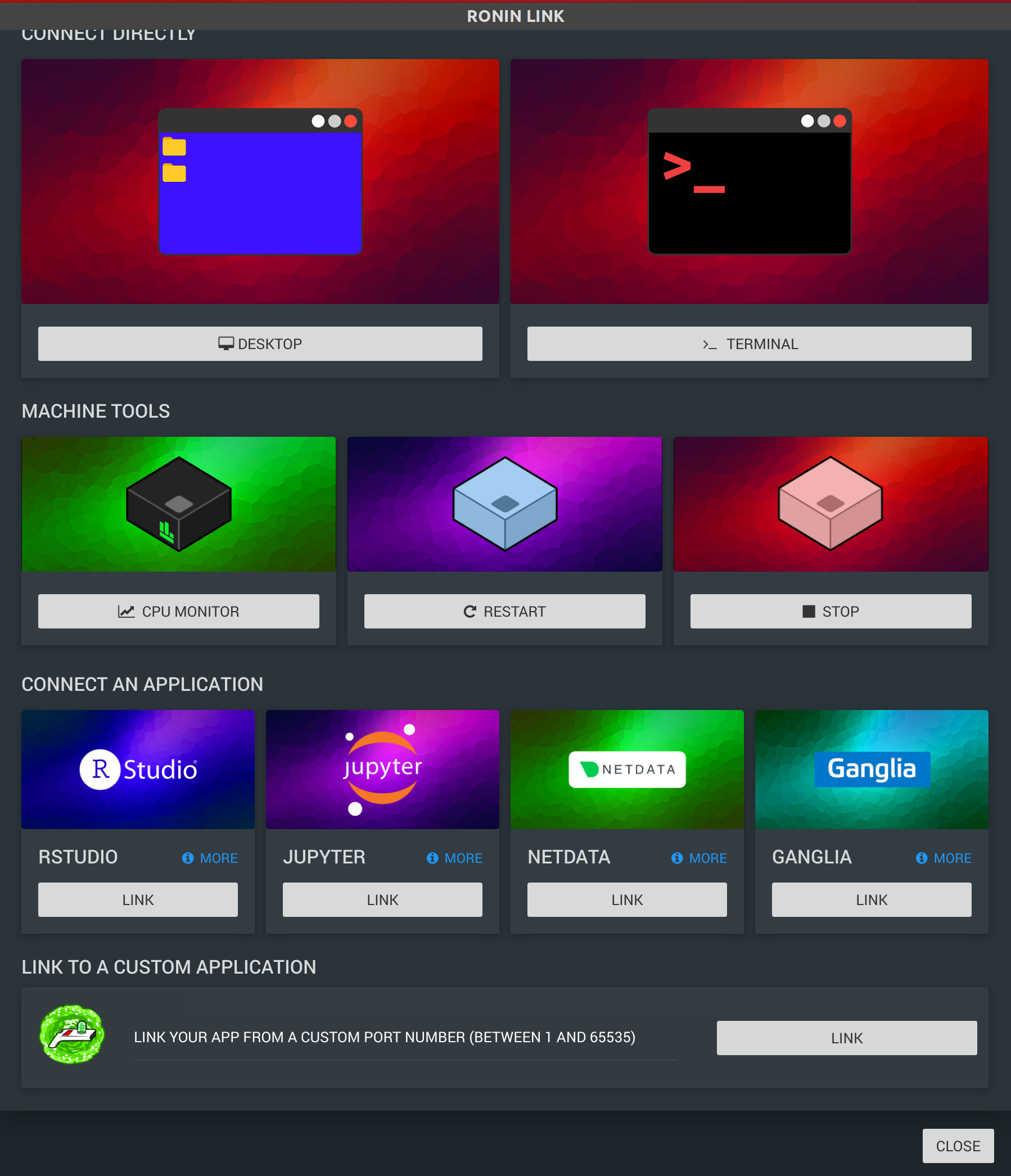
RONIN LINK
Once researchers have base machines, they will need new and different things to support their workflow. One researcher will need R Studio on a neuroimaging cluster to run statistics on the data. Another researcher will need a graphical desktop to visualize output on a genomics cluster. RONIN Link is an open source desktop application that allows researchers to install some of these common applications on supported operating systems with a push of a button, and securely connect to them through ssh port tunneling.
Project Packages
And finally, researchers will still want to customize their machines and clusters by installing additional things — Python or R packages that they use, their favorite editors, and software and utilities specific to their workflow. There is no way to avoid that. But it's a safe bet researchers have installed this software before on their laptops, and it is less risky to do so on a cloud computer. This is because researchers can back up or package their machines when they are in a good working state, and if something goes wrong, they can revert back to their last working version, or the package catalog origin. No one else is impacted by a botched install.
Packaged machines are not just for research IT to disseminate across RONIN. Researchers can package machines and clusters with everything that they want for a specific project. The packages can be shared by a researcher with only the other project members. Once pipelines are working correctly, the package becomes a reference for the project members to use to conduct their own analyses. When papers are completed, the packages used for analysis can be saved together with the data to ensure reproducibility. This package becomes a reference for the future, when the analysis needs to be conducted on new data or with a different algorithm, or simply shared with other researchers.
Ultimately, when we talk about supporting research computing on the cloud, we have to talk about shifting from controlled and shared computing environments to enabling and supporting self-service research. This brings IT closer to the chaos and diversity of researcher software stacks, but also closer to helping researchers move quickly to configure the machines they need to achieve their goals. And isn't that what we should be talking about?
