Connect R to Object Storage
There's so much research data out there and R is a popular way to mash it up, scrape it down, run statistics on it and make it beautiful. You can access research data available in object storage buckets directly from within R....



There's so much research data out there and R is a popular way to mash it up, scrape it down, run statistics on it and make it beautiful. You can access research data available in object storage buckets directly from within R. These can be your own object stores within RONIN that you access securely, protected data stored on Amazon S3 for which you obtain a key, or open data stored on Amazon S3. You can even add your own data or results to object stores within R, as long as you have the necessary permissions for that bucket.
You will need Rstudio running on a machine. If you don't know how, check out our blog on creating an Rstudio machine in RONIN.
Gather all the things
You need a few bits of information before you start. You will need the downloaded csv file that was created when you made your object store (e.g. bucket.store.ronin.cloud.csv, where bucket should be the name of YOUR bucket). This file has the AccessKeyID and the SecretAccessKey that you will use to configure your credentials.
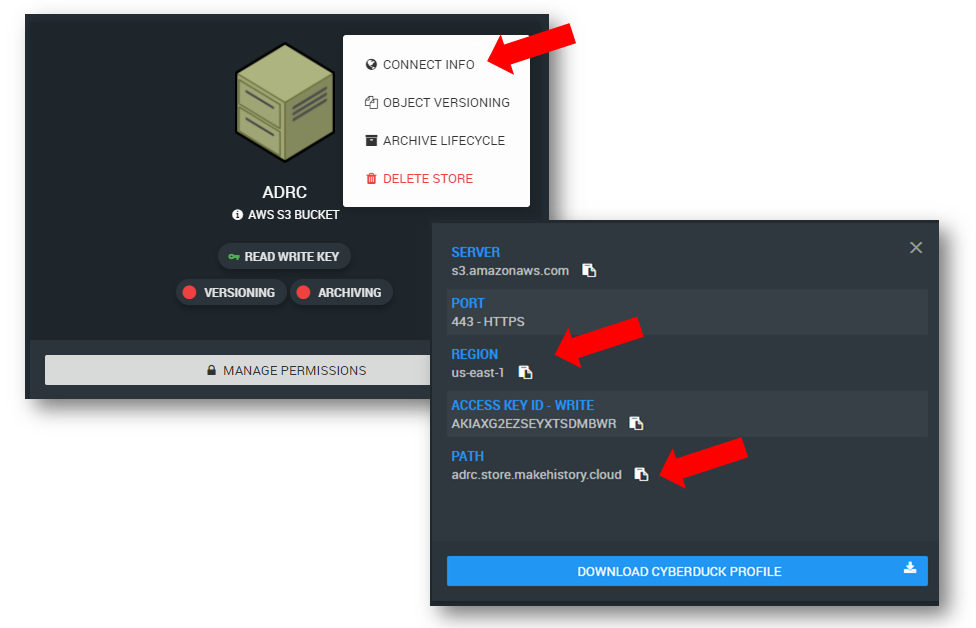
You will also need to know the Path and the Region for your bucket. You can obtain these by going to the Object Storage menu in RONIN, clicking on the dots in the upper right for your bucket, and looking at the REGION in the "Connect Info" menu (as shown below). Here, the Region is "us-east-1" and the Path name is "adrc.store.makehistory.cloud" as shown below.
Configure R to access the object storage bucket
After you have opened up an Rstudio window, install a package to read/write object stores. There are a few such packages, but here we will use the package aws.s3. Within R, install and load the package:
install.packages("aws.s3")
library(aws.s3)
Now you need to configure your credentials to connect R to your S3 bucket. In the sample code below, replace our example AWS_ACCESS_KEY_ID with your AccessKeyId, and replace the AWS_SECRET_ACCESS_KEY with your SecretAccessKey. Finally, replace the AWS_DEFAULT_REGION with your Region.
Sys.setenv(
"AWS_ACCESS_KEY_ID" = "AKIAXG2EZSEYR5XXXXXX",
"AWS_SECRET_ACCESS_KEY"= "dbhQIXUsRsA5SqNL5Gu8fqMjNPZy6EgUJEXXXXXX",
"AWS_DEFAULT_REGION" = "us-east-1"
)
Every character counts and missing the first or last can cause a lot of frustration. We're looking out for you.
Once you have configured your environment, you can access the object store from within R as follows. Replace our example bucket path (adrc.store.makehistory.cloud) with your bucket's Path that you retrieved earlier.
get_bucket(bucket='adrc.store.makehistory.cloud')
This will return a structure with information about all of the objects in the store.
Write files to object storage
We can write a data table to object storage with two steps. First, we take the famous iris data set and write it to a temporary file that we create. Second, we use the put_object call to move this file to our bucket.
# write the iris data to a temporary file
write.csv(iris, file.path(tempdir(), "iris.csv"))
# then write it to the bucket
put_object(
file = file.path(tempdir(), "iris.csv"),
object = "iris.csv",
bucket = "adrc.store.makehistory.cloud"
)
Read files from object storage
Thankfully, reading comma-separated value file directly from an object store takes only one step. To read the iris data set back, you can type:
dat <- s3read_using(FUN = read.csv,
bucket = "adrc.store.makehistory.cloud",
object = "iris.csv")
Access open AWS S3 buckets
AWS has lots of open data available on the Registry of Open Data (RODA) that can be used for research, class projects, tutorials on reading open data, and so on. To access open data, you do not need your AccessKeyId and SecretAccessKey. But you will need to know the Region and the Path.
If you do not reset these variables just right, you will get a variety of inscrutable errors. If you do, come back here and read carefully.
As an example we will use the Humor Detection from Product Questions Answering Systems. This data set contains flippant and humorous questions about products, and serious questions, used by the authors to train a deep learning framework.
The Path for this data set is the last component in the "Amazon Resource Name" after the three colons, or "humor-detection-pds". Intuitive, right? The Region is right beneath, and it is "us-west-2".
Now to see and read the bucket contents, you need to unset your AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables, and you need to reset your AWS_DEFAULT_REGION environment variable.
# unset these environment variables
Sys.unsetenv("AWS_ACCESS_KEY_ID")
Sys.unsetenv("AWS_SECRET_ACCESS_KEY")
# set our region to that of the open bucket
Sys.setenv("AWS_DEFAULT_REGION"="us-west-2")
#read the contents of the bucket
contents <- get_bucket("humor-detection-pds")
#read one of the files therein
dat <- s3read_using(FUN = read.csv, bucket = "humor-detection-pds", object = contents[1]$Contents$Key) That's it! Now you can access storage that is big enough to match the Rstudio compute engine of your dreams.

The R logo is reproduced without modification under the Creative Commons Attribution-ShareAlike 4.0 International license(CC-BY-SA 4.0).