New Machine or New Autoscaling Cluster? Which Should I Choose?


When you begin to work with RONIN you are immediately faced with a choice — do you create a new machine? Or an autoscaling cluster? And what is the difference and why do you have to choose at all?
Machines
A machine is a single computer, even though it can have multiple virtual CPUs (cores) and therefore can run many things at the same time. When creating a machine you can select the type and desired number of of CPUs, the amount of memory you want, and whether you need any specialized hardware such as physically attached instance storage or GPUs. Because you're only working with the one machine, you run all of your commands and scripts directly from the command line, rather than submitting jobs to a scheduler to run elsewhere.
Autoscaling Clusters
An autoscaling cluster is a single computer (a head node) as above that is connected to some number of other computers (compute nodes) that can be deployed like an army of computing clones to do your bidding. When you submit jobs from the head node into a queue (using a queue manager such as slurm), compute nodes are created to do the work, and terminate when the work is completed. The number of compute nodes is flexible — you can specify a minimum number of compute nodes that are always running, and a maximum number of compute nodes, to limit how large the cluster can grow.
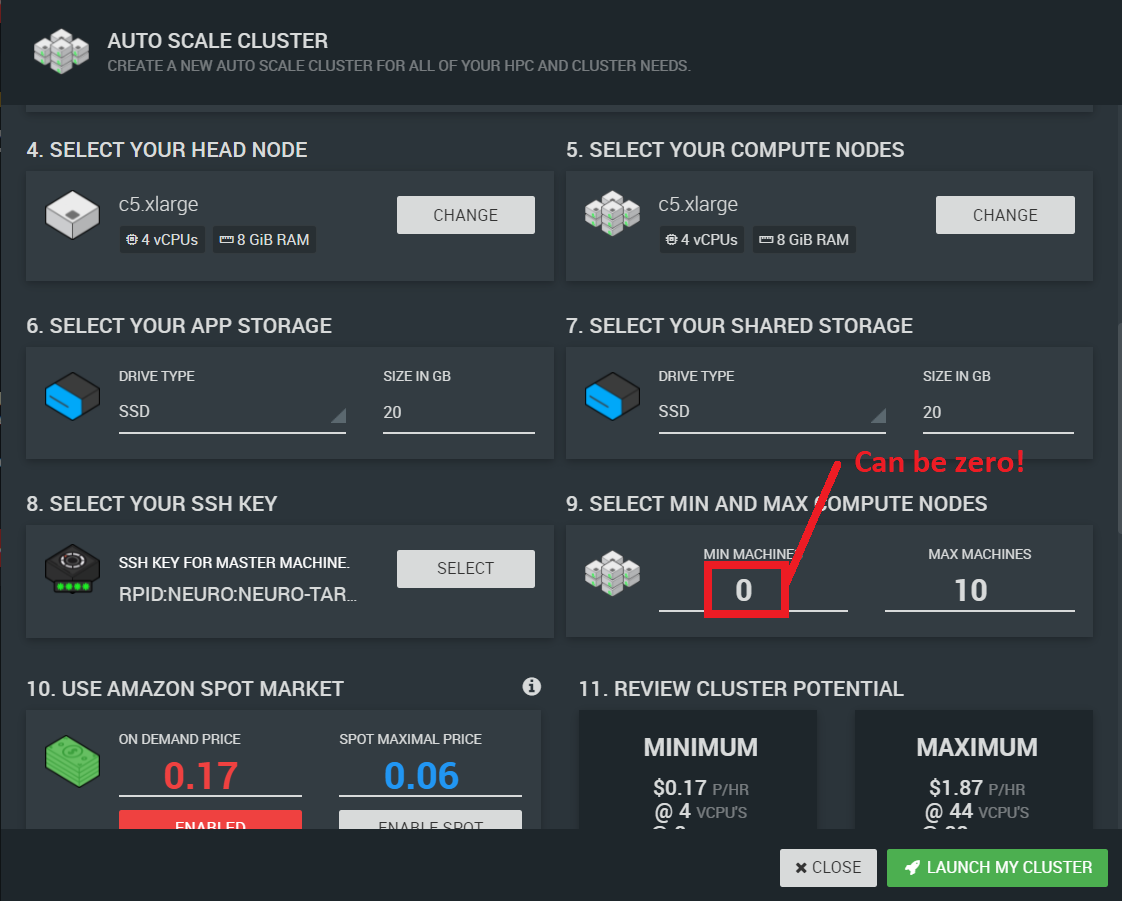
You can use an autoscaling cluster just like a machine by specifying a minimum number of compute nodes to be zero, as shown above. But you cannot turn a machine into a cluster. This is because a cluster comes with additional software to handle the queueing and autoscaling features, and has some shared drives to make it easier to install software and access data.
How do I choose?
Before you install and test all the software packages that you need for your research, think about the compute power you need. If the one analysis (sample, image, simulation, permutation test) you are trying to run is likely to turn into bajillions (when you get more data, or when you have fine-tuned your methodology), start with an autoscaling cluster. If instead you are working on a single analysis (for example, a statistical group analysis in R or Python), you might just want to create a machine. Machines are simpler, you have more choices for what operating system you want to choose, and they require less storage.
Software Installation
It is also important to think about where you install software in an autoscaling cluster vs a single machine. By default, there are three drives used by a cluster: /apps (for software), /shared (for shared data) and the root drive (everything that is not located in one of those other two directories). The /apps and /shared directories are shared with the head node and every compute node, so all nodes see the single copy of new software and data that are placed in those directories immediately.
On a cluster, the best thing to do is to install your software in
/apps and set your PATH environment variable to find your programs there. Write your analyses to place output files in unique directories or files in /shared. This approach allows you to make changes to your software quickly and organize your storage space efficiently.
However, most instructions that you find for installing scientific software assume the software goes in the root drive — in directories such as /usr/bin and /usr/local/bin — because that is the most logical place to install it on your laptop or desktop. But any changes made to the root drive on the head node after the cluster is launched will not automatically be reflected on the compute nodes, meaning your compute nodes won't be able to find your newly-installed software. If figuring out how to install your software in /apps would require a brown belt in Linux system administration, no worries! There is a way to use software that you install in the root drive with your cluster, but to do so you need to (1) package your cluster, (2) relaunch your cluster using the package. Upon relaunch, the compute nodes that are created will have their own copy of all the software installed on the head node root drive. This process takes about an hour, and be aware that if you install new software on the head node root drive, you will need to repackage and relaunch your cluster for that software to be visible to the compute nodes.
Finally, in the cloud computers come and go, and there is always time to change your mind. When you work out what you want to install, save those commands, and you will have a head start on your next computational creation.
